
Abstract
我们提出了一种新颖的、概念上简单的通用框架,用于在3D点云上进行实例分割。我们的方法称为3D-BoNet,遵循每点多层感知器(MLP)的简单设计理念。该框架直接回归点云中所有实例的3D边界框,同时预测每个实例的点级(point-level)掩码。它由一个主干网络和两个并行网络分支组成,用于1)边界框回归和2)点掩码预测。3D-BoNet是单阶段、anchor-free和端到端可训练的。此外,它的计算效率非常高,因为与现有方法不同,它不需要任何后处理步骤,例如非极大值抑制、特征采样、聚类或投票。大量实验表明,我们的方法超越了ScanNet和S3DIS数据集上的现有工作,同时计算效率提高了大约10倍。综合消融研究证明了我们设计的有效性。
1 Introduction
使机器能够理解3D场景是自动驾驶、增强现实和机器人技术的基本必要条件。点云等3D几何数据的核心问题包括语义分割、目标检测和实例分割。在这些问题中,实例分割在文献中才开始得到解决。主要障碍是点云本质上是无序的、非结构化的和不均匀的。广泛使用的卷积神经网络需要对3D点云进行体素化,从而产生高计算和内存成本。
第一个直接处理3D实例分割的神经算法是SGPN [50],它通过相似度矩阵学习对每个点的特征进行分组。类似地,ASIS [51]、JSIS3D[34]、MASC[30]、3D-BEVIS[8]和[28]将相同的每点特征分组pipeline应用于分割3D实例。 Mo等人将实例分割表述为PartNet[32]中的逐点特征分类问题。然而,这些proposal-free方法的学习片段不具有很高的对象性,因为它们没有明确地检测目标边界。此外,它们不可避免地需要后处理步骤,例如均值偏移聚类[6]来获得最终的实例标签,这在计算上是繁重的。另一个pipeline是基于proposal的3D-SIS[15]和GSPN[58],它们通常依靠两阶段训练和昂贵的非最大抑制来修剪密集目标proposal。
在本文中,我们提出了一个优雅、高效和新颖的3D实例分割框架,通过使用高效的MLPs的单前向阶段,对物体进行松散但唯一的检测,然后通过一个简单的点级二进制分类器对每个实例进行精确分割。为此,我们引入了一个新的边界框预测模块以及一系列精心设计的损失函数来直接学习目标边界。我们的框架与现有的基于proposal和proposal-free的方法有很大不同,因为我们能够有效地分割所有具有高目标性的实例,但不依赖于昂贵且密集的目标proposal。我们的代码和数据可在https://github.com/Yang7879/3D-BoNet获得。
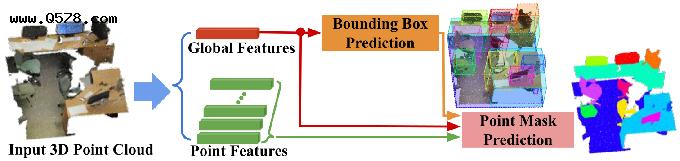
图 1:在3D点云上进行实例分割的3D-BoNet框架。
边界框预测分支是我们框架的核心。该分支旨在为single forward阶段中的每个实例预测一个唯一的、无方向的矩形边界框,而不依赖于预定义的空间anchors或区域proposal网络[39]。如图2所示,我们认为为实例粗略绘制3D边界框是相对可以实现的,因为输入点云明确包含3D几何信息,而在处理点级实例分割之前非常有益,因为合理的边界框可以保证学习片段的高度目标性。然而,学习实例框涉及到关键问题:1)总实例的数量是可变的,即从1到许多,2)所有实例没有固定的顺序。这些问题对正确优化网络提出了巨大挑战,因为没有信息可以直接将预测框与ground truth标签联系起来以监督网络。但是,我们展示了如何优雅地解决这些问题。这个框预测分支简单地将全局特征向量作为输入,并直接输出大量固定数量的边界框以及置信度分数。这些分数用于指示框是否包含有效实例。为了监督网络,我们设计了一个新颖的边界框关联层,然后是一个多标准损失函数。给定一组ground-truth实例,我们需要确定哪个预测框最适合它们。我们将此关联过程表述为具有现有求解器的最优分配问题。在框被最佳关联之后,我们的多准则损失函数不仅最小化了配对框的欧几里德距离,而且最大化了预测框内有效点的覆盖率。
图 2:粗略的实例框。
然后将预测的框与点和全局特征一起输入到后续的点掩码预测分支中,以便为每个实例预测一个点级二进制掩码。这个分支的目的是分类边界框内的每个点是属于有效实例还是背景。假设估计的实例框相当好,很可能获得准确的点掩码,因为这个分支只是拒绝不属于检测到的实例的点。随机猜测可能会带来50%的修正。
总体而言,我们的框架在三个方面与所有现有的3D实例分割方法不同。1)与proposal-free pipeline相比,我们的方法通过显式学习3D目标边界来分割具有高目标性的实例。2)与广泛使用的基于proposal的方法相比,我们的框架不需要昂贵且密集的proposal。3)我们的框架非常高效,因为实例级(instance-level)掩码是在单次前向(single-forward)传递中学习的,不需要任何后处理步骤。我们的主要贡献是:
- 我们提出了一个在3D点云上进行实例分割的新框架。该框架是单阶段、anchor-free和端到端可训练的,不需要任何后处理步骤。
- 我们设计了一个新颖的边界框关联层,然后是一个多标准损失函数来监督框预测分支。
- 我们展示了对baselines的显着改进,并通过广泛的消融研究为我们的设计选择提供了直觉依据。
图 3:3D-BoNet框架的一般工作流程。
2 3D-BoNet
2.1 Overview
2.2 Bounding Box Prediction
「边界框编码:」 在现有的目标检测网络中,边界框通常由中心位置和三个维度的长度[3]或对应的残差[60]以及方向来表示。相反,为简单起见,我们仅通过两个min-max顶点参数化矩形边界框:
图 4:边界框回归分支的架构。在计算多标准损失之前,预测的个框与个ground truth框最佳关联。
为了解决上述最优关联问题,现有的Hungarian算法[20;21]应用。关联矩阵计算:为了评估第个预测框和第个ground truth之间的相似性,一个简单直观的标准是两对最小-最大顶点之间的欧几里德距离。然而,它不是最优的。基本上,我们希望预测框包含尽可能多的有效点。如图5所示,输入点云通常是稀疏的,并且在3D空间中分布不均匀。对于相同的ground truth框#0(蓝色),候选框#2(红色)被认为比候选框#1(黑色)要好得多,因为框#2有更多的有效点与#0重叠。因此,在计算cost矩阵时,应包括有效点的覆盖范围。在本文中,我们考虑以下三个标准:
图 5:稀疏输入点云。
2.3 Point Mask Prediction
表 1ScanNet(v2)基准(隐藏测试集)上的实例分割结果。度量标准是IoU阈值为0.5的AP(%)。于2019年6月2日访问
图 6:点掩码预测分支的架构。点特征与每个边界框和分数融合,然后为每个实例预测一个point-level二进制掩码
2.4 End-to-End Implementation
3 Experiments
3.1 Evaluation on ScanNet Benchmark
我们首先在ScanNet(v2) 3D语义实例分割基准[7]上评估我们的方法。与SGPN[50]类似,我们将原始输入点云分成1mx1m块进行训练,同时使用所有点进行测试,然后使用BlockMerging算法[50]将块组装成完整的3D场景。在我们的实验中,我们观察到基于vanilla PointNet++的语义预测子分支的性能有限,无法提供令人满意的语义。由于我们框架的灵活性,我们因此可以轻松地训练一个并行SCN网络[11]来为我们的3D-BoNet的预测实例估计更准确的每点语义标签。IoU阈值为0.5的平均精度(AP)用作评估指标。
我们与表1中18个目标类别的领先方法进行了比较。特别是,SGPN[50]、3D-BEVIS[8]、MASC[30]和[28]是基于点特征聚类的方法;RPointNet[58]学习生成密集目标proposals,然后进行点级分割;3D-SIS[15]是一种基于proposal的方法,使用点云和彩色图像作为输入。PanopticFusion[33]学习通过Mask-RCNN[13]在多个2D图像上分割实例,然后使用SLAM系统重新投影回3D空间。我们的方法仅使用点云就超越了它们。值得注意的是,我们的框架在所有类别上的表现都相对令人满意,而不偏爱特定的类,这证明了我们框架的优越性。
图7:这显示了一个包含数百个目标(例如椅子、桌子)的演讲室,突出了实例分割的挑战。不同的颜色表示不同的实例。同一个实例可能有不同的颜色。我们的框架比其他框架预测更精确的实例标签。
3.2 Evaluation on S3DIS Dataset
我们进一步评估了我们框架在S3DIS[1]上的语义实例分割,其中包括来自6个大区域的271个房间的3D完整扫描。我们的数据预处理和实验设置严格遵循PointNet[37]、SGPN[50]、ASIS[51]和JSIS3D[34]。在我们的实验中,H设置为24,我们遵循6倍评估[1; 51]。
我们与ASIS[51]、S3DIS上的最新技术和PartNet baseline[32]进行比较。为了公平比较,我们使用与我们框架中使用的相同PointNet++主干和其他设置仔细训练PartNet baseline。为了评估,报告了IoU阈值为0.5的经典指标平均精度(mPrec)和平均召回率(mRec)。请注意,对于我们的方法和PartNet基线,我们使用相同的BlockMerging算法[50]来合并来自不同块的实例。最终分数是总共13个类别的平均值。表2显示了mPrec/mRec分数,图7显示了定性结果。我们的方法大大超过了PartNet baseline[32],并且也优于ASIS[51],但并不显着,主要是因为我们的语义预测分支(基于vanilla PointNet++)不如ASIS,后者紧密融合语义和实例特征以实现相互优化。我们将特征融合作为我们未来的探索
表 2:S3DIS 数据集上的实例分割结果。
3.3 Ablation Study
为了评估我们框架每个组件的有效性,我们在S3DIS数据集的最大区域5上进行了6组消融实验。
表3:S3DIS区域5上所有消融实验的实例分割结果。
「分析。」 表3显示了消融实验的分数。(1) box score子分支确实有利于整体实例分割性能,因为它倾向于惩罚重复的box预测。(2)与欧几里得距离和交叉熵得分相比,由于我们的可微算法1,框关联和监督的sIoU成本往往更好。由于三个单独的标准更喜欢不同类型的点结构,因此三个简单的组合在特定数据集上,标准可能并不总是最优的。(3)如果没有对框预测的监督,性能会显着下降,主要是因为网络无法推断出令人满意的实例3D边界,并且预测点掩码的质量相应下降。(4)与focal loss相比,由于实例和背景点数的不平衡,标准交叉熵损失对点掩码预测的效果较差。
3.4 Computation Analysis
4 Related Work
为了从3D点云中提取特征,传统方法通常手动制作特征[5; 42]。最近基于学习的方法主要包括基于体素的[42;46; 41; 23; 40; 11; 4]和基于点的方案[37;19; 14; 16; 45]。
「Semantic Segmentation」 PointNet[37]显示了分类和语义分割的领先结果,但它没有捕获上下文特征。为了解决这个问题,许多方法[38; 57; 43; 31; 55; 49; 26; 17]最近被提出。另一个管道是基于卷积核的方法[55; 27; 47]。基本上,这些方法中的大多数都可以用作我们的骨干网络,并与我们的3D-BoNet并行训练以学习每点语义。
「Object Detection」 在3D点云中检测目标的常用方法是将点投影到2D图像上以回归边界框[25;48; 3;56; 59; 53]。通过融合[3]中的RGB图像,检测性能进一步提高融合RGB图像[3;54;36;52].。点云也可以分为体素用于目标检测[9;24; 60]。然而,这些方法中的大多数都依赖于预定义的锚点和两阶段区域proposal网络[39]。在3D点云上扩展它们是低效的。在不依赖anchors的情况下,最近的PointRCNN[44]学习通过前景点分割进行检测,而VoteNet[35]通过点特征分组、采样和投票来检测目标。相比之下,我们的框预测分支与它们完全不同。我们的框架通过单次前向传递直接从紧凑的全局特征中回归3D目标边界框。
「Instance Segmentation」 SGPN[50]是第一个通过对point-level嵌入进行分组来分割3D点云实例的神经算法。ASIS[51]、JSIS3D[34]、MASC[30]、3D-BEVIS[8]和[28]使用相同的策略对点级特征进行分组,例如实例分割。Mo等人通过对点特征进行分类,在PartNet[32]中引入了一种分割算法。然而,这些proposal-free方法的学习片段不具有很高的目标性,因为它没有明确地检测目标边界。通过借鉴成功的2D RPN[39]和RoI [13],GSPN[58]和3D-SIS[15]是基于proposal的3D实例分割方法。但是,它们通常依赖于两阶段训练和一个后处理步骤来进行密集提议修剪。相比之下,我们的框架直接为明确检测到的对象边界内的每个实例预测一个point-level掩码,而不需要任何后处理步骤。
5 Conclusion
我们的框架简单、有效且高效,可用于3D点云上的实例分割。但是,它也有一些限制,导致未来的工作。(1)与其使用三个准则的未加权组合,不如设计一个模块来自动学习权重,以适应不同类型的输入点云。(2)可以引入更高级的特征融合模块来相互改进语义和实例分割,而不是训练单独的分支进行语义预测。(3)我们的框架遵循MLP设计,因此与输入点的数量和顺序无关。通过借鉴最近的工作[10][22],直接在大规模输入点云上而不是分割的小块上进行训练和测试是可取的。
原文链接:https://arxiv.org/abs/1906.01140
References
[1] I. Armeni, O. Sener, A. Zamir, and H. Jiang. 3D Semantic Parsing of Large-Scale Indoor Spaces. CVPR, 2016.
[2] Y . Bengio, N. Léonard, and A. Courville. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. arXiv, 2013.
[3] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-View 3D Object Detection Network for Autonomous Driving. CVPR, 2017.
[4] C. Choy, J. Gwak, and S. Savarese. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. CVPR, 2019.
[5] C. S. Chua and R. Jarvis. Point signatures: A new representation for 3d object recognition. IJCV, 25(1):63–85, 1997.
[6] D. Comaniciu and P . Meer. Mean Shift: A Robust Approach toward Feature Space Analysis. TPAMI, 24(5):603–619, 2002.
[7] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. CVPR, 2017.
[8] C. Elich, F. Engelmann, J. Schult, T. Kontogianni, and B. Leibe. 3D-BEVIS: Birds-Eye-View Instance Segmentation. GCPR, 2019.
[9] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner. V ote3Deep: Fast Object Detection in 3D Point Clouds Using Efficient Convolutional Neural Networks. ICRA, 2017.
[10] F. Engelmann, T. Kontogianni, A. Hermans, and B. Leibe. Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds. ICCV Workshops, 2017.
[11] B. Graham, M. Engelcke, and L. v. d. Maaten. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. CVPR, 2018.
[12] A. Grover, E. Wang, A. Zweig, and S. Ermon. Stochastic Optimization of Sorting Networks via Continuous Relaxations. ICLR, 2019.
[13] K. He, G. Gkioxari, P . Dollar, and R. Girshick. Mask R-CNN. ICCV, 2017.
[14] P . Hermosilla, T. Ritschel, P .-P . V azquez, A. Vinacua, and T. Ropinski. Monte Carlo Convolution for Learning on Non-Uniformly Sampled Point Clouds. ACM Transactions on Graphics, 2018.
[15] J. Hou, A. Dai, and M. Nießner. 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans. CVPR, 2019.
[16] B.-S. Hua, M.-K. Tran, and S.-K. Yeung. Pointwise Convolutional Neural Networks. CVPR, 2018.
[17] Q. Huang, W. Wang, and U. Neumann. Recurrent Slice Networks for 3D Segmentation of Point Clouds. CVPR, 2018.
[18] D. P . Kingma and J. Ba. Adam: A method for stochastic optimization. ICLR, 2015.
[19] R. Klokov and V . Lempitsky. Escape from Cells: Deep Kd-Networks for The Recognition of 3D Point Cloud Models. ICCV, 2017.
[20] H. W. Kuhn. The Hungarian Method for the assignment problem. Naval Research Logistics Quarterly, 2(1-2):83–97, 1955.
[21] H. W. Kuhn. V ariants of the hungarian method for assignment problems. Naval Research Logistics Quarterly, 3(4):253–258, 1956.
[22] L. Landrieu and M. Simonovsky. Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs. CVPR, 2018.
[23] T. Le and Y . Duan. PointGrid: A Deep Network for 3D Shape Understanding. CVPR, 2018.
[24] B. Li. 3D Fully Convolutional Network for V ehicle Detection in Point Cloud. IROS, 2017.
[25] B. Li, T. Zhang, and T. Xia. V ehicle Detection from 3D Lidar Using Fully Convolutional Network. RSS, 2016.
[26] J. Li, B. M. Chen, and G. H. Lee. SO-Net: Self-Organizing Network for Point Cloud Analysis. CVPR, 2018.
[27] Y . Li, R. Bu, M. Sun, W. Wu, X. Di, and B. Chen. PointCNN : Convolution On X -Transformed Points. NeurlPS, 2018.
[28] Z. Liang, M. Yang, and C. Wang. 3D Graph Embedding Learning with a Structure-aware Loss Function for Point Cloud Semantic Instance Segmentation. arXiv, 2019.
[29] T.-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Dollar. Focal Loss for Dense Object Detection. ICCV, 2017.
[30] C. Liu and Y . Furukawa. MASC: Multi-scale Affinity with Sparse Convolution for 3D Instance Segmentation. arXiv, 2019.
[31] S. Liu, S. Xie, Z. Chen, and Z. Tu. Attentional ShapeContextNet for Point Cloud Recognition. CVPR, 2018.
[32] K. Mo, S. Zhu, A. X. Chang, L. Yi, S. Tripathi, L. J. Guibas, and H. Su. PartNet: A Large-scale Benchmark for Fine-grained and Hierarchical Part-level 3D Object Understanding. CVPR, 2019.
[33] G. Narita, T. Seno, T. Ishikawa, and Y . Kaji. PanopticFusion: Online V olumetric Semantic Mapping at the Level of Stuff and Things. IROS, 2019.
[34] Q.-H. Pham, D. T. Nguyen, B.-S. Hua, G. Roig, and S.-K. Yeung. JSIS3D: Joint Semantic-Instance Segmentation of 3D Point Clouds with Multi-Task Pointwise Networks and Multi-V alue Conditional Random Fields. CVPR, 2019.
[35] C. R. Qi, O. Litany, K. He, and L. J. Guibas. Deep Hough V oting for 3D Object Detection in Point Clouds. ICCV, 2019.
[36] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas. Frustum PointNets for 3D Object Detection from RGB-D Data. CVPR, 2018.
[37] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. CVPR, 2017.
[38] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. NIPS, 2017.
[39] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. NIPS, 2015.
[40] D. Rethage, J. Wald, J. Sturm, N. Navab, and F. Tombari. Fully-Convolutional Point Networks for Large-Scale Point Clouds. ECCV, 2018.
[41] G. Riegler, A. O. Ulusoy, and A. Geiger. OctNet: Learning Deep 3D Representations at High Resolutions. CVPR, 2017.
[42] R. B. Rusu, N. Blodow, and M. Beetz. Fast point feature histograms (fpfh) for 3d registration. ICRA, 2009.
[43] Y . Shen, C. Feng, Y . Yang, and D. Tian. Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling. CVPR, 2018.
[44] S. Shi, X. Wang, and H. Li. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. CVPR, 2019.
[45] H. Su, V . Jampani, D. Sun, S. Maji, E. Kalogerakis, M.-H. Y ang, and J. Kautz. SPLA TNet: Sparse Lattice Networks for Point Cloud Processing. CVPR, 2018.
[46] L. P . Tchapmi, C. B. Choy, I. Armeni, J. Gwak, and S. Savarese. SEGCloud: Semantic Segmentation of 3D Point Clouds. 3DV, 2017.
[47] H. Thomas, C. R. Qi, J.-E. Deschaud, B. Marcotegui, F. Goulette, and L. J. Guibas. KPConv: Flexible and Deformable Convolution for Point Clouds. ICCV, 2019.
[48] V . V aquero, I. Del Pino, F. Moreno-Noguer, J. Soì, A. Sanfeliu, and J. Andrade-Cetto. Deconvolutional Networks for Point-Cloud V ehicle Detection and Tracking in Driving Scenarios. ECMR, 2017.
[49] C. Wang, B. Samari, and K. Siddiqi. Local Spectral Graph Convolution for Point Set Feature Learning. ECCV, 2018.
[50] W. Wang, R. Y u, Q. Huang, and U. Neumann. SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation. CVPR, 2018.
[51] X. Wang, S. Liu, X. Shen, C. Shen, and J. Jia. Associatively Segmenting Instances and Semantics in Point Clouds. CVPR, 2019.
[52] Z. Wang, W. Zhan, and M. Tomizuka. Fusing Bird View LIDAR Point Cloud and Front View Camera Image for Deep Object Detection. arXiv, 2018.
[53] B. Wu, A. Wan, X. Y ue, and K. Keutzer. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. arXiv, 2017.
[54] D. Xu, D. Anguelov, and A. Jain. PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation. CVPR, 2018.
[55] Y . Xu, T. Fan, M. Xu, L. Zeng, and Y . Qiao. SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters. ECCV, 2018.
[56] G. Yang, Y . Cui, S. Belongie, and B. Hariharan. Learning Single-View 3D Reconstruction with Limited Pose Supervision. ECCV, 2018.
[57] X. Ye, J. Li, H. Huang, L. Du, and X. Zhang. 3D Recurrent Neural Networks with Context Fusion for Point Cloud Semantic Segmentation. ECCV, 2018.
[58] L. Yi, W. Zhao, H. Wang, M. Sung, and L. Guibas. GSPN: Generative Shape Proposal Network for 3D Instance Segmentation in Point Cloud. CVPR, 2019.
[59] Y . Zeng, Y . Hu, S. Liu, J. Y e, Y . Han, X. Li, and N. Sun. RT3D: Real-Time 3D V ehicle Detection in LiDAR Point Cloud for Autonomous Driving. IEEE Robotics and Automation Letters, 3(4):3434–3440, 2018.
[60] Y . Zhou and O. Tuzel. V oxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. CVPR, 2018.
