
编辑:好困 LRS
【新智元导读】今天给大家安利一个宝藏仓库miemiedetection ,该仓库集合了PPYOLO、PPYOLOv2、PPYOLOE三个算法pytorch实现三合一,其中的PPYOLOv2和PPYOLO算法刚刚支持了导出ncnn。
众所周知,PPYOLO和PPYOLOv2的导出部署非常困难,因为它们使用了可变形卷积、MatrixNMS等对部署不太友好的算子。
而作者在ncnn中实现了可变形卷积DCNv2、CoordConcat、PPYOLO Decode MatrixNMS等自定义层,使得使用ncnn部署PPYOLO和PPYOLOv2成为了可能。其中的可变形卷积层也已经被合入ncnn官方仓库。
在ncnn中对图片预处理时,先将图片从BGR格式转成RGB格式,然后用cv2.INTER_CUBIC方式将图片插值成640×640的大小,再使用相同的均值和标准差对图片进行归一化。以上全部与原版PPYOLOv2一样,从而确保了C++端和python端输入神经网络的图片张量是完全一样的。
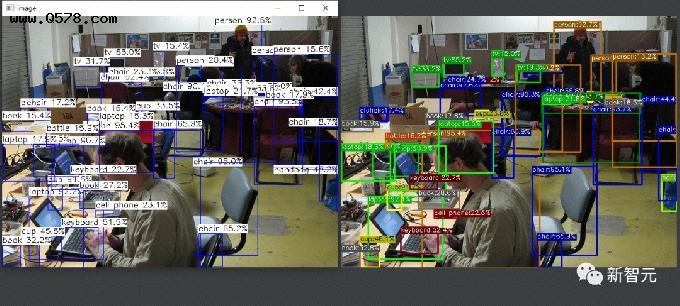
最后,ncnn的输出与miemiedetection的输出对比如下图所示:
其中,右边是miemiedetection的输出,为ppyolov2_r50vd_365e.pth这个模型预测的结果。在miemiedetection根目录下输入以下内容即可得到。
python tools/demo.py image -f exps/ppyolo/ppyolov2_r50vd_365e.py -c ppyolov2_r50vd_365e.pth –path assets/000000013659.jpg –conf 0.15 –tsize 640 –save_result –device gpu
左边则是ncnn相同的模型ppyolov2_r50vd_365e的结果,ncnn的运算结果与pytorch有细微差别,影响不大。
pytorch直接转ncnn
读了一部分ncnn的源码,确保对 *.bin 和 *.param 文件充分了解之后,封装了1个工具ncnn_utils,源码位于miemiedetection的mmdet/models/ncnn_utils.py,它支持写一次前向传播就能导出ncnn使用的 *.bin 和 *.param 文件,你只需给每个pytorch层增加1个export_ncnn()方法,export_ncnn()方法几乎只要照抄farward()方法就能把模型导出到ncnn。
以下是ncnn_utils工具的使用示例:
是不是很牛x?你只要照着farward()方法写,在export_ncnn()方法里用ncnn_utils的api写一次前向传播就能把pytorch模型导出到ncnn。
在这个示例中,我展示了如何将resnet中使用的ConvNormLayer层导出到ncnn,ConvNormLayer层里包含了卷积层、bn层、激活层(当self.dcn_v2==False),或者是卷积层、可变形卷积层、bn层、激活层(当self.dcn_v2==True)。
为了提升ncnn的推理速度,我将卷积层(可变形卷积层)和bn层合并,另外,当激活函数是relu、leakyrelu、clip、sigmoid、mish、hardswish这些时,还可以将激活层合并到卷积层当中,这样就将3个层合并成了1个层,大大提高推理速度。
可变形卷积
卷积层可以视为可变形卷积在offset==0,mask==1时的特例。
一个形状为[in_c, h, w]的特征图inputs,经过普通卷积层(卷积核形状是[num_output, in_c, kernel_h, kernel_w],w方向的步长、相邻卷积采样点的距离、卷积步长、左填充、右填充分别是kernel_w、dilation_w、stride_w、pad_left、pad_right,h方向的步长、相邻卷积采样点的距离、卷积步长、上填充、下填充分别是kernel_h、dilation_h、stride_h、pad_top、pad_bottom)后,得到的特征图形状是[num_output, out_h, out_w],其中out_h = (h + pad_top + pad_bottom – dilation_h * (kernel_h – 1) + 1) / stride_h + 1,out_w = (w + pad_left + pad_right – dilation_w * (kernel_w – 1) + 1) / stride_w + 1。
一个形状为[in_c, h, w]的特征图inputs,经过可变形卷积层(卷积核形状是[num_output, in_c, kernel_h, kernel_w],w方向的步长、相邻卷积采样点的距离、卷积步长、左填充、右填充分别是kernel_w、dilation_w、stride_w、pad_left、pad_right,h方向的步长、相邻卷积采样点的距离、卷积步长、上填充、下填充分别是kernel_h、dilation_h、stride_h、pad_top、pad_bottom)后,得到的特征图形状也是[num_output, out_h, out_w],其中out_h = (h + pad_top + pad_bottom – dilation_h * (kernel_h – 1) + 1) / stride_h + 1,out_w = (w + pad_left + pad_right – dilation_w * (kernel_w – 1) + 1) / stride_w + 1。
但不同的是在可变形卷积层之前,inputs需要经过一个普通卷积层,获得可变形卷积需要的offset和mask,offset和mask的形状分别是[kernel_h * kernel_w * 2, out_h, out_w]、[kernel_h * kernel_w, out_h, out_w]。为什么是这个形状呢?
我们知道,inputs经过卷积层,卷积窗是不是滑动了out_h * out_w次?是的,因为每一行卷积窗滑动了out_w次,每一列卷积窗滑动了out_h次,所以总共滑动了out_h * out_w次。
此外,卷积采样点是不是有kernel_h * kernel_w个?
是的,offset表示的是卷积窗停留在每一个位置的时候,每个卷积采样点的偏移(有y、x两个坐标),所以offset的形状是[kernel_h * kernel_w * 2, out_h, out_w]。
但是,offset是浮点数,你怎么取原图inputs里的像素?双线性插值!对采样点的x、y坐标分别进行上取整和下取整,得到最近的4个采样点的坐标,然后将4个采样点的像素进行双线性插值,得到所求的像素val。
mask是0到1之间的值(进入可变形卷积层之前会经过sigmoid层),表示的是每个val的重要程度,所以它的形状是[kernel_h * kernel_w, out_h, out_w]。
offset和mask会和inputs一起进入可变形卷积层参与后续计算。
「talk is cheap, show me the code」,我们来看一下ncnn中可变形卷积的代码!
…#include “deformableconv2d.h”#include “fused_activation.h”namespace ncnn {DeformableConv2D::DeformableConv2D(){ one_blob_only = false; support_inplace = false;}int DeformableConv2D::load_param(const ParamDict& pd){ num_output = pd.get(0, 0); kernel_w = pd.get(1, 0); kernel_h = pd.get(11, kernel_w); dilation_w = pd.get(2, 1); dilation_h = pd.get(12, dilation_w); stride_w = pd.get(3, 1); stride_h = pd.get(13, stride_w); pad_left = pd.get(4, 0); pad_right = pd.get(15, pad_left); pad_top = pd.get(14, pad_left); pad_bottom = pd.get(16, pad_top); bias_term = pd.get(5, 0); weight_data_size = pd.get(6, 0); activation_type = pd.get(9, 0); activation_params = pd.get(10, Mat()); return 0;}int DeformableConv2D::load_model(const ModelBin& mb){ weight_data = mb.load(weight_data_size, 0); if (weight_data.empty()) return -100; if (bias_term) { bias_data = mb.load(num_output, 1); if (bias_data.empty()) return -100; } return 0;}int DeformableConv2D::forward(const std::vector& bottom_blobs, std::vector& top_blobs, const Option& opt) const{ const Mat& bottom_blob = bottom_blobs[0]; const Mat& offset = bottom_blobs[1]; const bool has_mask = (bottom_blobs.size() == 3); const int w = bottom_blob.w; const int h = bottom_blob.h; const int in_c = bottom_blob.c; const size_t elemsize = bottom_blob.elemsize; const int kernel_extent_w = dilation_w * (kernel_w – 1) + 1; const int kernel_extent_h = dilation_h * (kernel_h – 1) + 1; const int out_w = (w + pad_left + pad_right – kernel_extent_w) / stride_w + 1; const int out_h = (h + pad_top + pad_bottom – kernel_extent_h) / stride_h + 1; // output.shape is [num_output, out_h, out_w] (in python). Mat& output = top_blobs[0]; output.create(out_w, out_h, num_output, elemsize, opt.blob_allocator); if (output.empty()) return -100; const float* weight_ptr = weight_data; const float* bias_ptr = weight_data; if (bias_term) bias_ptr = bias_data; // deformable conv #pragma omp parallel for num_threads(opt.num_threads) for (int h_col = 0; h_col < out_h; h_col++) { for (int w_col = 0; w_col < out_w; w_col++) { int h_in = h_col * stride_h – pad_top; int w_in = w_col * stride_w – pad_left; for (int oc = 0; oc < num_output; oc++) { float sum = 0.f; if (bias_term) sum = bias_ptr[oc]; for (int i = 0; i -1 && h_im = 0); v2_cond = (h_low >= 0 && w_high <= w – 1); v3_cond = (h_high = 0); v4_cond = (h_high <= h – 1 && w_high <= w – 1); w1 = hh * hw; w2 = hh * lw; w3 = lh * hw; w4 = lh * lw; } for (int c_im = 0; c_im < in_c; c_im++) { float val = 0.f; if (cond) { float v1 = v1_cond ? bottom_blob.channel(c_im).row(h_low)[w_low] : 0.f; float v2 = v2_cond ? bottom_blob.channel(c_im).row(h_low)[w_high] : 0.f; float v3 = v3_cond ? bottom_blob.channel(c_im).row(h_high)[w_low] : 0.f; float v4 = v4_cond ? bottom_blob.channel(c_im).row(h_high)[w_high] : 0.f; val = w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4; } sum += val * mask_ * weight_ptr[((oc * in_c + c_im) * kernel_h + i) * kernel_w + j]; } } } output.channel(oc).row(h_col)[w_col] = activation_ss(sum, activation_type, activation_params); } } } return 0;}} // namespace ncnn
forward()函数即可变形卷积的前向代码,bottom_blobs是可变形卷积的输入,当bottom_blobs里有3个输入时,分别是inputs、offset、mask,表示是DCNv2,当bottom_blobs里有2个输入时,分别是inputs、offset,表示是DCNv1。
接下来的代码,我计算了out_h、out_w,即输出特征图的高度和宽度。接下来是对输出张量output开辟空间,获取可变形卷积层的权重、偏置的指针weight_ptr、bias_ptr。最后进入for循环。
第1个for循环表示的是卷积窗在h方向滑动,滑了out_h次。
第2个for循环表示的是卷积窗在w方向滑动,滑了out_w次;之后计算的h_in、w_in分别表示当前卷积窗位置左上角采样点在pad之后的inputs的y坐标、x坐标(实际上inputs不需要pad,之后你会看到,采样点超出inputs的范围时,采样得到的像素强制取0)。
第3个for循环表示的是填写输出特征图的每一个通道,填了num_output次;首先让sum=0,当使用偏置时,sum=bias_ptr[oc],即第oc个偏置。
第4、第5、第6个for循环遍历了卷积核的高度、宽度、通道数,计算卷积层权重weight每个卷积采样点每个通道和原图inputs相应位置的像素val(双线性插值得到)和积,再累加到sum中。offset_h、offset_w是当前卷积采样点的y、x偏移,mask_是双线性插值得到的val的重要程度。
真正采样位置的y坐标是h_im = 当前卷积窗左上角y坐标h_in + 卷积核内部y偏移i * dilation_h + y偏移offset_h;真正采样位置的x坐标是w_im = 当前卷积窗左上角x坐标w_in + 卷积核内部x偏移j * dilation_w + x偏移offset_w。
之后,计算好双线性插值中h_im、w_im上下取整的结果h_low、w_low、h_high、w_high,双线性插值中4个像素的权重w1、w2、w3、w4等。注意,不要在for (int c_im = 0; c_im < in_c; c_im++){}中计算,因为在每一个输入通道中,采样位置h_im、w_im是相等的,所以h_low、w_low、h_high、w_high、w1、w2、w3、w4也是相等的,提前计算好就不用在每个输入通道重复计算,提高计算速度和算法效率。
第6个for循环中,遍历每个输入通道,求采样得到像素val,如果采样位置超出inputs的范围,取0;对比cond和v1_cond、v2_cond、v3_cond、v4_cond,会发现cond的边界会比v1_cond、v2_cond、v3_cond、v4_cond的边界大一点,比如当h_im==-1且w_im==-1时, cond是true。
这是因为,h_im和w_im会经过上下取整,其中上取整得到的采样点位置是(0, 0),刚好是在inputs范围内,所以cond的边界会比v1_cond、v2_cond、v3_cond、v4_cond的边界大一点。
计算好val之后,将val * mask_ * weight_ptr[((oc * in_c + c_im) * kernel_h + i) * kernel_w + j]累加到sum之中。
PPYOLOv2输出解码
PPYOLOv2输出解码比YOLOv3复杂一些,它使用了iou_aware和Grid Sensitive。
在YOLOv3中,输出3个特征图,表示3种感受野(大中小)的预测结果,每个特征图的每个格子输出3个bbox,对应3个聚类出来的anchor进行解码。
当数据集类别数是80时候,YOLOv3每个特征图通道数是3 * (4+1+80),3表示每个格子输出3个bbox,4表示未解码的xywh,1表示未解码的objness,80表示80个类别未解码的条件概率。PPYOLOv2使用了iou_aware,每个特征图通道数是3 * (1+4+1+80),即每个bbox多出1个ioup属性。共有258个通道,但是前3个通道才是每个bbox的ioup,后255个通道和YOLOv3的排列一样。
通过阅读IouAwareLoss的代码,ioup使用F.binary_cross_entropy_with_logits()训练,解码时需要用sigmoid()激活,使用当前预测框和它所学习的gt的iou作为监督信息,所以ioup其实预测的是当前预测框和它所学习的gt的iou。所以,当然是希望ioup越大越好。
在mmdet(ppdet)中,用了1条曲线救国的道路对输出解码:
# mmdet/models/heads/yolov3_head.py… if self.iou_aware: na = len(self.anchors[i]) ioup, x = out[:, 0:na, :, :], out[:, na:, :, :] b, c, h, w = x.shape no = c // na x = x.reshape((b, na, no, h * w)) ioup = ioup.reshape((b, na, 1, h * w)) obj = x[:, :, 4:5, :] ioup = torch.sigmoid(ioup) obj = torch.sigmoid(obj) obj_t = (obj**(1 – self.iou_aware_factor)) * ( ioup**self.iou_aware_factor) obj_t = _de_sigmoid(obj_t) loc_t = x[:, :, :4, :] cls_t = x[:, :, 5:, :] y_t = torch.cat([loc_t, obj_t, cls_t], 2) out = y_t.reshape((b, c, h, w)) box, score = paddle_yolo_box(out, self._anchors[self.anchor_masks[i]], self.downsample[i], self.num_classes, self.scale_x_y, im_size, self.clip_bbox, conf_thresh=self.nms_cfg[‘score_threshold’])
即分别对ioup和obj进行sigmoid激活,再obj_t = (obj ** (1 – self.iou_aware_factor)) * (ioup ** self.iou_aware_factor)作为新的obj,新的obj经过sigmoid的反函数还原成未接码状态,未接码的新obj贴回x中。最后out的通道数是255,只要像原版YOLOv3那样解码out就行了。
这么做的原因是paddle_yolo_box()的作用是对原版YOLOv3的输出进行解码,充分利用paddle_yolo_box()的话就不用自己写解码的代码。所以就走了曲线救国的道路。
从中我们可以得到一些信息,ioup只不过是和obj经过表达式obj_t = (obj ** (1 – self.iou_aware_factor)) * (ioup ** self.iou_aware_factor)得到新的obj,其余只要像YOLOv3一样解码就ok了!
所以在ncnn中,我这样实现PPYOLOv2的解码:
// examples/test2_06_ppyolo_ncnn.cpp…class PPYOLODecodeMatrixNMS : public ncnn::Layer{public: PPYOLODecodeMatrixNMS() { // miemie2013: if num of input tensors > 1 or num of output tensors > 1, you must set one_blob_only = false // And ncnn will use forward(const std::vector& bottom_blobs, std::vector& top_blobs, const Option& opt) method // or forward_inplace(std::vector& bottom_top_blobs, const Option& opt) method one_blob_only = false; support_inplace = false; } virtual int load_param(const ncnn::ParamDict& pd) { num_classes = pd.get(0, 80); anchors = pd.get(1, ncnn::Mat()); strides = pd.get(2, ncnn::Mat()); scale_x_y = pd.get(3, 1.f); iou_aware_factor = pd.get(4, 0.5f); score_threshold = pd.get(5, 0.1f); anchor_per_stride = pd.get(6, 3); post_threshold = pd.get(7, 0.1f); nms_top_k = pd.get(8, 500); keep_top_k = pd.get(9, 100); kernel = pd.get(10, 0); gaussian_sigma = pd.get(11, 2.f); return 0; } virtual int forward(const std::vector& bottom_blobs, std::vector& top_blobs, const ncnn::Option& opt) const { const ncnn::Mat& bottom_blob = bottom_blobs[0]; const int tensor_num = bottom_blobs.size() – 1; const size_t elemsize = bottom_blob.elemsize; const ncnn::Mat& im_scale = bottom_blobs[tensor_num]; const float scale_x = im_scale[0]; const float scale_y = im_scale[1]; int out_num = 0; for (size_t b = 0; b < tensor_num; b++) { const ncnn::Mat& tensor = bottom_blobs[b]; const int w = tensor.w; const int h = tensor.h; out_num += anchor_per_stride * h * w; } ncnn::Mat bboxes; bboxes.create(4 * out_num, elemsize, opt.blob_allocator); if (bboxes.empty()) return -100; ncnn::Mat scores; scores.create(num_classes * out_num, elemsize, opt.blob_allocator); if (scores.empty()) return -100; float* bboxes_ptr = bboxes; float* scores_ptr = scores; // decode for (size_t b = 0; b < tensor_num; b++) { const ncnn::Mat& tensor = bottom_blobs[b]; const int w = tensor.w; const int h = tensor.h; const int c = tensor.c; const bool use_iou_aware = (c == anchor_per_stride * (num_classes + 6)); const int channel_stride = use_iou_aware ? (c / anchor_per_stride) – 1 : (c / anchor_per_stride); const int cx_pos = use_iou_aware ? anchor_per_stride : 0; const int cy_pos = use_iou_aware ? anchor_per_stride + 1 : 1; const int w_pos = use_iou_aware ? anchor_per_stride + 2 : 2; const int h_pos = use_iou_aware ? anchor_per_stride + 3 : 3; const int obj_pos = use_iou_aware ? anchor_per_stride + 4 : 4; const int cls_pos = use_iou_aware ? anchor_per_stride + 5 : 5; float stride = strides[b]; #pragma omp parallel for num_threads(opt.num_threads) for (int i = 0; i < h; i++) { for (int j = 0; j < w; j++) { for (int k = 0; k score_threshold) { // Grid Sensitive float cx = static_cast(scale_x_y / (1.f + expf(-tensor.channel(cx_pos + k * channel_stride).row(i)[j])) + j – (scale_x_y – 1.f) * 0.5f); float cy = static_cast(scale_x_y / (1.f + expf(-tensor.channel(cy_pos + k * channel_stride).row(i)[j])) + i – (scale_x_y – 1.f) * 0.5f); cx *= stride; cy *= stride; float dw = static_cast(expf(tensor.channel(w_pos + k * channel_stride).row(i)[j]) * anchors[(b * anchor_per_stride + k) * 2]); float dh = static_cast(expf(tensor.channel(h_pos + k * channel_stride).row(i)[j]) * anchors[(b * anchor_per_stride + k) * 2 + 1]); float x0 = cx – dw * 0.5f; float y0 = cy – dh * 0.5f; float x1 = cx + dw * 0.5f; float y1 = cy + dh * 0.5f; bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4] = x0 / scale_x; bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4 + 1] = y0 / scale_y; bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4 + 2] = x1 / scale_x; bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4 + 3] = y1 / scale_y; for (int r = 0; r < num_classes; r++) { float score = static_cast(obj / (1.f + expf(-tensor.channel(cls_pos + k * channel_stride + r).row(i)[j]))); scores_ptr[((i * w + j) * anchor_per_stride + k) * num_classes + r] = score; } }else { bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4] = 0.f; bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4 + 1] = 0.f; bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4 + 2] = 1.f; bboxes_ptr[((i * w + j) * anchor_per_stride + k) * 4 + 3] = 1.f; for (int r = 0; r < num_classes; r++) { scores_ptr[((i * w + j) * anchor_per_stride + k) * num_classes + r] = -1.f; } } } } } bboxes_ptr += h * w * anchor_per_stride * 4; scores_ptr += h * w * anchor_per_stride * num_classes; }…
只要在obj那里动手脚,其余像YOLOv3那样解码就行了,而且,只对obj > score_threshold的bbox解码,其余bbox敷衍处理,提升后处理速度。
Grid Sensitive的提出是为了解决训练过程中gt中心点落在格子线上的问题,它允许解码后的x、y超出0~1的范围一点点。
MatrixNMS
MatrixNMS为实例分割SOLO中提出的nms算法,原版MatrixNMS非常巧妙地通过一个矩阵乘法求掩码两两之间的iou,只需将求掩码两两之间的iou改成求预测框两两之间的iou,即可将MatrixNMS应用于目标检测算法的后处理。
MatrixNMS的优点是不用设置nms_iou这个比较敏感的超参数;以及,理论速度比multiclass_nms快,因为它用了矩阵乘法求掩码两两之间的iou,矩阵乘法可用gpu并行高速计算;multiclass_nms对每个类别会选出1个得分最高的预测框(该预测框肯定会保留下来),然后分别与得分比它低的同类预测框计算iou,iou高于nms_iou的将会被舍弃,然后进行第二次迭代,从剩余的预测框里再次选出得分最高的,重复上述过程。
multiclass_nms需要进行多次迭代,每一次迭代依赖于上一次迭代,无法做到并行,因为你不能提前预知哪个预测框会被保留。MatrixNMS就没有这种迭代过程,其理论速度要快于multiclass_nms。
MatrixNMS采用了「减分」机制,对于每一个类别的每一个预测框,如果和得分比它高的同类预测框有iou(重叠),它的得分会被扣掉一些,之后,通过post_threshold分数阈值过滤掉低分数的预测框,剩下的就是最后的预测框了。
「talk is cheap, show me the code」,我们来看一下ncnn中MatrixNMS的代码!
// examples/test2_06_ppyolo_ncnn.cpp…struct Bbox{ float x0; float y0; float x1; float y1; int clsid; float score;};bool compare_desc(Bbox bbox1, Bbox bbox2){ return bbox1.score > bbox2.score;}float calc_iou(Bbox bbox1, Bbox bbox2){ float area_1 = (bbox1.y1 – bbox1.y0) * (bbox1.x1 – bbox1.x0); float area_2 = (bbox2.y1 – bbox2.y0) * (bbox2.x1 – bbox2.x0); float inter_x0 = std::max(bbox1.x0, bbox2.x0); float inter_y0 = std::max(bbox1.y0, bbox2.y0); float inter_x1 = std::min(bbox1.x1, bbox2.x1); float inter_y1 = std::min(bbox1.y1, bbox2.y1); float inter_w = std::max(0.f, inter_x1 – inter_x0); float inter_h = std::max(0.f, inter_y1 – inter_y0); float inter_area = inter_w * inter_h; float union_area = area_1 + area_2 – inter_area + 0.000000001f; return inter_area / union_area;}…class PPYOLODecodeMatrixNMS : public ncnn::Layer{public:… virtual int forward(const std::vector& bottom_blobs, std::vector& top_blobs, const ncnn::Option& opt) const { … // keep bbox whose score > score_threshold std::vector bboxes_vec; for (int i = 0; i < out_num; i++) { float x0 = bboxes[i * 4]; float y0 = bboxes[i * 4 + 1]; float x1 = bboxes[i * 4 + 2]; float y1 = bboxes[i * 4 + 3]; for (int j = 0; j score_threshold) { Bbox bbox; bbox.x0 = x0; bbox.y0 = y0; bbox.x1 = x1; bbox.y1 = y1; bbox.clsid = j; bbox.score = score; bboxes_vec.push_back(bbox); } } } if (bboxes_vec.size() == 0) { ncnn::Mat& pred = top_blobs[0]; pred.create(0, 0, elemsize, opt.blob_allocator); if (pred.empty()) return -100; return 0; } // sort and keep top nms_top_k int nms_top_k_ = nms_top_k; if (bboxes_vec.size() nms_top_k) bboxes_vec.resize(nms_top_k); // ———————- Matrix NMS ———————- // calc a iou matrix whose shape is [n, n], n is bboxes_vec.size() int n = bboxes_vec.size(); float* decay_iou = new float[n * n]; for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { if (j < i + 1) { decay_iou[i * n + j] = 0.f; }else { bool same_clsid = bboxes_vec[i].clsid == bboxes_vec[j].clsid; if (same_clsid) { float iou = calc_iou(bboxes_vec[i], bboxes_vec[j]); decay_iou[i * n + j] = iou; }else { decay_iou[i * n + j] = 0.f; } } } } // get max iou of each col float* compensate_iou = new float[n]; for (int i = 0; i < n; i++) { float max_iou = decay_iou[i]; for (int j = 0; j max_iou) max_iou = decay_iou[j * n + i]; } compensate_iou[i] = max_iou; } float* decay_matrix = new float[n * n]; // get min decay_value of each col float* decay_coefficient = new float[n]; if (kernel == 0) // gaussian { for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { decay_matrix[i * n + j] = static_cast(expf(gaussian_sigma * (compensate_iou[i] * compensate_iou[i] – decay_iou[i * n + j] * decay_iou[i * n + j]))); } } }else if (kernel == 1) // linear { for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { decay_matrix[i * n + j] = (1.f – decay_iou[i * n + j]) / (1.f – compensate_iou[i]); } } } for (int i = 0; i < n; i++) { float min_v = decay_matrix[i]; for (int j = 0; j < n; j++) { if (decay_matrix[j * n + i] < min_v) min_v = decay_matrix[j * n + i]; } decay_coefficient[i] = min_v; } for (int i = 0; i < n; i++) { bboxes_vec[i].score *= decay_coefficient[i]; } // ———————- Matrix NMS (end) ———————- std::vector bboxes_vec_keep; for (int i = 0; i post_threshold) { bboxes_vec_keep.push_back(bboxes_vec[i]); } } n = bboxes_vec_keep.size(); if (n == 0) { ncnn::Mat& pred = top_blobs[0]; pred.create(0, 0, elemsize, opt.blob_allocator); if (pred.empty()) return -100; return 0; } // sort and keep keep_top_k int keep_top_k_ = keep_top_k; if (n keep_top_k) bboxes_vec_keep.resize(keep_top_k); ncnn::Mat& pred = top_blobs[0]; pred.create(6 * n, elemsize, opt.blob_allocator); if (pred.empty()) return -100; float* pred_ptr = pred; for (int i = 0; i < n; i++) { pred_ptr[i * 6] = (float)bboxes_vec_keep[i].clsid; pred_ptr[i * 6 + 1] = bboxes_vec_keep[i].score; pred_ptr[i * 6 + 2] = bboxes_vec_keep[i].x0; pred_ptr[i * 6 + 3] = bboxes_vec_keep[i].y0; pred_ptr[i * 6 + 4] = bboxes_vec_keep[i].x1; pred_ptr[i * 6 + 5] = bboxes_vec_keep[i].y1; } pred = pred.reshape(6, n); return 0; }…
第一步,将得分超过score_threshold的预测框保存到bboxes_vec里,这是第一次分数过滤;如果没有预测框的得分超过score_threshold,直接返回1个形状是(0, 0)的Mat代表没有物体。
第二步,将bboxes_vec中的前nms_top_k个预测框按照得分降序排列,bboxes_vec中只保留前nms_top_k个预测框。
第三步,进入MatrixNMS,设此时bboxes_vec里有n个预测框,我们计算一个n * n的矩阵decay_iou,下三角部分(包括对角线)是0,表示的是bboxes_vec中的预测框两两之间的iou,而且,只计算同类别预测框的iou,非同类的预测框iou置为0;
接下来的代码比较难以理解,我举个例子说明,比如经过第一次分数过滤和得分降序排列后,剩下编号为0、1、2的3个同类的预测框,假设此时的decay_iou值为:
如果某个预测框与比它分高的同类预测框有较高的iou,它应该减去更多的分,这该怎么实现呢?
一个比较简单的做法是对矩阵1-decay_iou每一列求最小值,即对矩阵:
每一列求最小,得到衰减系数向量decay_coefficient=[1, 0.1, 0.2],然后每个bbox的得分再和衰减系数向量里相应的值相乘,就实现减分的效果了!
比如0号预测框,它的得分应该乘以1,这很好理解,它是得分最高的预测框,应该被保留,不应该减分。
对于1号预测框,它的得分应该乘以0.1,这很好理解,它与0号预测框的iou高达0.9,应该减去很多分。
对于2号预测框,它的得分应该乘以0.2,这很好理解,它与1号预测框的iou高达0.8,应该减去很多分。
但是这样做真的正确吗?
如果用multiclass_nms做nms算法,假设设定的nms_iou=0.6,第0次迭代,首先保留得分最高的0号预测框,发现1号预测框和0号预测框的iou高达0.9,所以舍弃1号预测框,发现2号预测框和0号预测框的iou是0.2,保留2号预测框;第1次迭代,首先保留得分最高的2号预测框,发现没有预测框了,nms算法结束。所以最后保留的是0号预测框和2号预测框。
上面的分析中,仅仅是因为2号预测框与1号预测框的iou高达0.8,就让2号预测框的分数乘以0.2,是非常不正确的做法,因为1号预测框与0号预测框的iou高达0.9,1号预测框有很大概率是会被舍弃的,不能因为2号预测框与可能被舍弃的1号预测框的iou高达0.8,就让2号预测框减去很多分。
那么怎么解决这个问题呢?补偿!
1-0.8没有什么参考意义,我们应该将它放大,可以让它除以(1-0.9)实现,0.9表示1号预测框与0号预测框的iou高达0.9,这样逐列取最小的时候就可能取不到它了。而且,不应该只有1号预测框与2号预测框这么做,预测框两两之间都应该这么做。
我们看接下来的代码,逐列取decay_iou的最大值得到补偿向量compensate_iou,在这个示例中compensate_iou=[0, 0.9, 0.8],然后求一个n * n的矩阵decay_matrix,当kernel == 1时,是linear,它的计算公式是(1-decay_iou)矩阵的每一行元素都除以(1-compensate_iou的第i个值)(假设当前行id是i),所以在这个示例中,decay_matrix的值是:
逐列取decay_matrix的最小值,即可得到decay_coefficient=[1, 0.1, 0.8],你看,2号预测框的得分应该乘以0.8,是由于它和0号预测框的iou是0.2导致的,它减去的分数就比较少。而此时1号预测框和2号预测框在decay_matrix中的值被补偿(被放大)到2,参考意义不大,逐列取最小时取不到它。
现在你应该能更好地理解代码中decay_matrix的计算公式了吗?
decay_matrix[i * n + j] = (1.f – decay_iou[i * n + j]) / (1.f – compensate_iou[i]);
第i个预测框和第j个预测框的iou是decay_iou[i * n + j],第i个预测框它觉得第j个预测框的衰减系数应该是(1.f – decay_iou[i * n + j]),但是第i个预测框它觉得的就是对的吗?
还要看第i个预测框是否被抑制,第i个预测框如果没有被抑制,那么(1.f – decay_iou[i * n + j])就有参考意义,第i个预测框如果被抑制,那么(1.f – decay_iou[i * n + j])就没有什么参考意义。
所以需要除以(1.f – compensate_iou[i])作为补偿,compensate_iou[i]表示的是第i个预测框与比它分高的预测框的最高iou:
如果这个max_iou很大,衰减系数就会被放大,第i个预测框它觉得第j个预测框的衰减系数是xxx就没什么参考意义;如果这个max_iou很小,衰减系数就会放大得很小(max_iou==0时不放大),第i个预测框它觉得第j个预测框的衰减系数是xxx就有参考意义。
然后,逐列取decay_matrix的最小值,第j列的最小值应该是decay_iou[i * n + j]越大越好、compensate_iou[i]越小越好的那个第i个预测框提供。
当kernel == 0,也仅仅表示用其它的函数表示衰减系数和补偿而已。所有的预测框的得分乘以decay_coefficient相应的值实现减分,MatrixNMS结束。
第四步,将得分超过post_threshold的预测框保存到bboxes_vec_keep里,这是第二次分数过滤;如果没有预测框的得分超过post_threshold,直接返回1个形状是(0, 0)的Mat代表没有物体。
第五步,将bboxes_vec_keep中的前keep_top_k个预测框按照得分降序排列,bboxes_vec_keep中只保留前keep_top_k个预测框。
最后,写1个形状是(n, 6)的Mat表示最终所有的预测框后处理结束。
如何导出
(1)第一步,在miemiedetection根目录下输入这些命令下载paddle模型:
wget https://paddledet.bj.bcebos.com/models/ppyolo_r50vd_dcn_2x_coco.pdparamswget https://paddledet.bj.bcebos.com/models/ppyolo_r18vd_coco.pdparamswget https://paddledet.bj.bcebos.com/models/ppyolov2_r50vd_dcn_365e_coco.pdparamswget https://paddledet.bj.bcebos.com/models/ppyolov2_r101vd_dcn_365e_coco.pdparams
(2)第二步,在miemiedetection根目录下输入这些命令将paddle模型转pytorch模型:
python tools/convert_weights.py -f exps/ppyolo/ppyolo_r50vd_2x.py -c ppyolo_r50vd_dcn_2x_coco.pdparams -oc ppyolo_r50vd_2x.pth -nc 80python tools/convert_weights.py -f exps/ppyolo/ppyolo_r18vd.py -c ppyolo_r18vd_coco.pdparams -oc ppyolo_r18vd.pth -nc 80python tools/convert_weights.py -f exps/ppyolo/ppyolov2_r50vd_365e.py -c ppyolov2_r50vd_dcn_365e_coco.pdparams -oc ppyolov2_r50vd_365e.pth -nc 80python tools/convert_weights.py -f exps/ppyolo/ppyolov2_r101vd_365e.py -c ppyolov2_r101vd_dcn_365e_coco.pdparams -oc ppyolov2_r101vd_365e.pth -nc 80
(3)第三步,在miemiedetection根目录下输入这些命令将pytorch模型转ncnn模型:
python tools/demo.py ncnn -f exps/ppyolo/ppyolo_r18vd.py -c ppyolo_r18vd.pth –ncnn_output_path ppyolo_r18vd –conf 0.15python tools/demo.py ncnn -f exps/ppyolo/ppyolo_r50vd_2x.py -c ppyolo_r50vd_2x.pth –ncnn_output_path ppyolo_r50vd_2x –conf 0.15python tools/demo.py ncnn -f exps/ppyolo/ppyolov2_r50vd_365e.py -c ppyolov2_r50vd_365e.pth –ncnn_output_path ppyolov2_r50vd_365e –conf 0.15python tools/demo.py ncnn -f exps/ppyolo/ppyolov2_r101vd_365e.py -c ppyolov2_r101vd_365e.pth –ncnn_output_path ppyolov2_r101vd_365e –conf 0.15
-c代表读取的权重,–ncnn_output_path表示的是保存为NCNN所用的 *.param 和 *.bin 文件的文件名,–conf 0.15表示的是在PPYOLODecodeMatrixNMS层中将score_threshold和post_threshold设置为0.15,你可以在导出的 *.param 中修改score_threshold和post_threshold,分别是PPYOLODecodeMatrixNMS层的5=xxx 7=xxx属性。
然后,下载ncnn_ppyolov2 这个仓库(它自带了glslang和实现了ppyolov2推理),按照官方how-to-build 文档进行编译ncnn。
编译完成后, 将上文得到的ppyolov2_r50vd_365e.param、ppyolov2_r50vd_365e.bin、…这些文件复制到ncnn_ppyolov2的build/examples/目录下,最后在ncnn_ppyolov2根目录下运行以下命令进行ppyolov2的预测:
cd build/examples./test2_06_ppyolo_ncnn ../../my_tests/000000013659.jpg ppyolo_r18vd.param ppyolo_r18vd.bin 416./test2_06_ppyolo_ncnn ../../my_tests/000000013659.jpg ppyolo_r50vd_2x.param ppyolo_r50vd_2x.bin 608./test2_06_ppyolo_ncnn ../../my_tests/000000013659.jpg ppyolov2_r50vd_365e.param ppyolov2_r50vd_365e.bin 640./test2_06_ppyolo_ncnn ../../my_tests/000000013659.jpg ppyolov2_r101vd_365e.param ppyolov2_r101vd_365e.bin 640
每条命令最后1个参数416、608、640表示的是将图片resize到416、608、640进行推理,即target_size参数。会弹出一个这样的窗口展示预测结果:
test2_06_ppyolo_ncnn的源码位于ncnn_ppyolov2仓库的examples/test2_06_ppyolo_ncnn.cpp。
PPYOLOv2和PPYOLO算法目前在Linux和Windows平台均已成功预测。
