
前言
Cloud Native
我们能否绕开 http 协议,直接测试数据库的性能?是否觉得从数据库中导出 CSV 文件来构造压测数据很麻烦?怎样在压测结束后做数据清理?能不能通过数据库中的插入(删除)记录对压测请求做断言?使用阿里云性能测试工具 PTS 可以轻松解决上述问题。
什么是 JDBC
Cloud Native
JDBC(Java DataBase Connectivity,Java 数据库连接)是一种用于执行 SQL 语句的 Java API,可以为多种关系数据库提供统一访问,它由一组用 Java 语言编写的类和接口组成。JDBC 提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。
简单地说,JDBC 可做三件事:与数据库建立连接、发送操作数据库的语句并处理结果。
JDBC 的设计原理
Cloud Native
1
整体架构
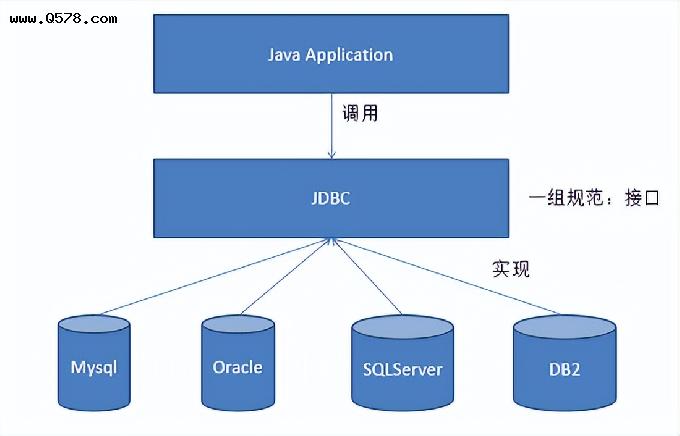
JDBC 制定了一套和数据库进行交互的标准,数据库厂商提供这套标准的实现,这样就可以通过统一的 JDBC 接口来连接各种不同的数据库。可以说 JDBC 的作用是屏蔽了底层数据库的差异,使得用户按照 JDBC 写的代码可以在各种不同的数据库上进行执行。那么这是如何实现的呢?如下图所示:
JDBC 定义了 Driver 接口,这个接口就是数据库的驱动程序, 所有跟数据库打交道的操作最后都会归结到这里 ,数据库厂商必须实现该接口,通过这个接口来完成上层应用的调用者和底层具体的数据库进行交互。Driver 是通过 JDBC 提供的 DriverManager 进行注册的,注册的代码写在了 Driver 的静态块中,如 MySQL 的注册代码如下所示:
static { try { java.sql.DriverManager.registerDriver(new Driver()); } catch (SQLException E) { throw new RuntimeException(“Can’t register driver!”); } }作为驱动定义的规范 Driver,它的主要目的就是和数据库建立连接,所以其接口也很简单,如下所示:public interface Driver { //建立连接 Connection connect(String url, java.util.Properties info) throws SQLException; boolean acceptsURL(String url) throws SQLException; DriverPropertyInfo[] getPropertyInfo(String url, java.util.Properties info) throws SQLException; int getMajorVersion(); int getMinorVersion(); boolean jdbcCompliant(); public Logger getParentLogger() throws SQLFeatureNotSupportedException;}
作为 Driver 的管理者 DriverManager,它不仅负责 Driver 的注册/注销,还可以直接获取连接。它是怎么做到的呢?观察下面代码发现,实际是通过遍历所以已经注册的 Driver,找到一个能够成功建立连接的 Driver,并且将 Connection 返回,DriverManager 就像代理一样,将真正建立连接的过程还是交给了具体的 Driver。
for(DriverInfo aDriver : registeredDrivers) { // If the caller does not have permission to load the driver then // skip it. if(isDriverAllowed(aDriver.driver, callerCL)) { try { println(” trying ” + aDriver.driver.getClass().getName()); Connection con = aDriver.driver.connect(url, info); if (con != null) { // Success! println(“getConnection returning ” + aDriver.driver.getClass().getName()); return (con); } } catch (SQLException ex) { if (reason == null) { reason = ex; } } } else { println(” skipping: ” + aDriver.getClass().getName()); } }
2
Connection 设计
通过上节我们知道数据库提供商通过实现Driver接口来向用户提供服务,Driver接口的核心方法就是获取连接。Connection是和数据库打交道的核心接口,下面我们看看它的设计方案。
通过观察设计图我们发现主要有两类接口:DataSource 和 Connection。下面我们逐一进行介绍。
- DataSource
直接看源码,如下所示,发现它的核心方法竟然和 Driver 一样,也是获取连接。那为什么还要 DataSource 呢?Driver 本身不就是获取连接的吗?下面我们就看看 DataSource 到底是怎么获取连接的。
public interface DataSource extends CommonDataSource, Wrapper { Connection getConnection() throws SQLException; Connection getConnection(String username, String password) throws SQLException;}
然而我们发现 JDBC 只定义了 DataSource 的接口,并没有给出具体实现,下面我们就以 Spring 实现的 SimpleDriverDataSource 为例,来看看它是怎么做的,代码如下所示,发现 DataSource 的 getConnection(…)方法,最后竟然还是交由 driver.connect(…)去真正建立连接。所以又回到最开始我们所描述的, Driver 才是真正的与数据库打交道的接口。
protected Connection getConnectionFromDriver(Properties props) throws SQLException { Driver driver = getDriver(); String url = getUrl(); Assert.notNull(driver, “Driver must not be null”); if (logger.isDebugEnabled()) { logger.debug(“Creating new JDBC Driver Connection to [” + url + “]”); } return driver.connect(url, props); }
那么问题来了,为什么还需要 DataSource 这样的接口,岂不多此一举么?显然不会。DataSource 是加强版的 Driver。它将核心的建立连接的过程交由 Driver 执行,而对于建立缓存,处理分布式事务和连接池等看似与建立连接无关的事情自己来处理。如类的设计图所示,以 PTS 使用的 Druid 连接池为例:
- ConnectionPoolDataSource:连接池的实现,此数据源实现并不直接创建数据库物理连接,而是一个逻辑实现,它的作用在于池化数据库物理连接。
- PooledConnection:配合 ConnectionPoolDataSource,由它获取一个池化对象 PooledConnection,再通过该 PooledConnection 间接获取到物理连接。
显然,通过连接池我们可以从连接的管理中抽身,提高连接的利用效率,也能提升压力机的施压能力。
3
Statement 设计
建立连接之后,用户可能要开始写 SQL 语句,并且交由数据库去执行了。这些是通过 Statement 来实现的。主要分为:
- Statement:定义一个静态的 SQL 语句,数据库每次执行都需要重新编译,一般用于仅执行一次查询并返回结果的情形。
- PreparedStatement:定义一个带参的预编译的 SQL 语句,下次执行时,会从缓存中取出遍以后的语句,而不需要重新编译一遍,适用于执行多次相同逻辑的 SQL 语句,当然它还有防 SQL 注入等功能,安全性和效率较高,使用比较频繁。对于性能测试来说,选择 PreparedStatement 最为合适。
- CallableStatement:用来调用存储过程。
4
ResultSet 设计
JDBC 使用 ResultSet 接口来承接 Statement 的执行结果。ResultSet 使用指针的方式(next())来逐条获取检索结果,当指针指向某条数据时,用户可以自由的选择获取某一列的数据。PTS 通过将 ResultSet 转化成 CSV 文件,辅助用户以一条 SQL 语句,构造复杂的压测数据。
5
JDBC 架构总结
通过上面的介绍我们发现,JDBC 的设计还是层次感分明的。
(1)Driver 和 DriverManager 是面向数据库的,设计了一套 Java 访问数据的规范,数据库厂商只需要实现这套规范即可;
(2)DataSource 和 Connection 是面向应用程序开发者的,它们不关心 JDBC 具体是如何跟数据库进行交互的,通过统一的 DataSource 接口就可以拿到 Connection,用户的数据操作都可以通过这个 Connection 来实现了;
(3)Statement 承载了具体的 SQL 命令,用户可以定义不同的 Statement 来向数据库发送指令;
(4)ResultSet 是用来承载 SQL 命令的执行结果。
至此,完成了 加载驱动 -> 建立连接 -> 执行命令 -> 返回结果 这样的和数据库交互的整个过程。如果把这个过程灵活的嵌入到 PTS 性能测试中,便可以解决前言提到的各种问题。
JDBC 在性能测试中的应用
Cloud Native
1
数据库性能测试
- 背景
大多数对数据库的操作都是通过 HTTP、FTP 或其他协议执行的,但是在某些情况下,绕开中间协议直接测试数据库也很有意义。例如我们希望不触发所有相关查询,而只测试特定 high-value 查询的性能;验证新数据库在高负载下的性能。2.验证某些数据库连接池参数,例如最大连接数 3.节省时间和资源。当我们想要优化 SQL 时,修改代码中的 SQL 语句和其他数据库操作非常繁琐,通过 JDBC 压测,我们可以避免侵入代码,集中精力在 SQL 调优上。
- 步骤
1、创建场景。 我们在 PTS 控制台的【压测中心】->【 创建场景 】中创建 PTS 压测场景;
2、场景配置。PTS 支持对 MySQL、PostgreSQL 等四种数据库发起压测。用户填写 JDBC URL、用户名、密码和 SQL 即可发起压测。同时,PTS 还支持提取 ResultSet 中的数据作为出参,给下游 API 使用;对响应进行断言。
3、压测中监控和压测报告。PTS 支持绑定阿里云 RDS 云资源监控,在压测过程中观察 RDS 实时性能指标。此外,PTS 还提供清晰完备的压测报告以及采样日志,供用户随时查看。
2
压测数据构造
- 背景
在模拟不同用户登录、压测业务参数传递等场景中,需要使用参数功能来实现压测的请求中各种动态操作。如果使用传统的 CSV 文件参数,会受到文件大小的限制,且手动创建耗费精力。使用 JDBC 来构造压测数据,可以避免以上问题。
- 步骤
1、 添加数据源。 在场景编辑-数据源管理中,选择添加 DB 数据源,输入 URL、用户名、密码和 SQL。
2、添加参数。填写自定义参数名和列索引。
3、调试验证。点击调试场景,即可验证提取的结果集是否符合预期。接着,我们就可以在任意想要使用参数的地方使用${}引用即可。
3
压测脏数据清理
- 背景
针对写请求的压测,会在数据库中生成大量脏数据。如何在压测结束后自动清理?
- 步骤
PTS 给用户提供了解决方案。PTS 支持对串联链路作逻辑上的顺序编排,即前置链路、普通链路和后置链路。执行顺序由先到后。设置某条串联链路为后置链路,填写循环次数即可。
