
前言
前面我们进行了很多的理论性研究,下面我们开始用代码进行实现。
编程求解线性SVM
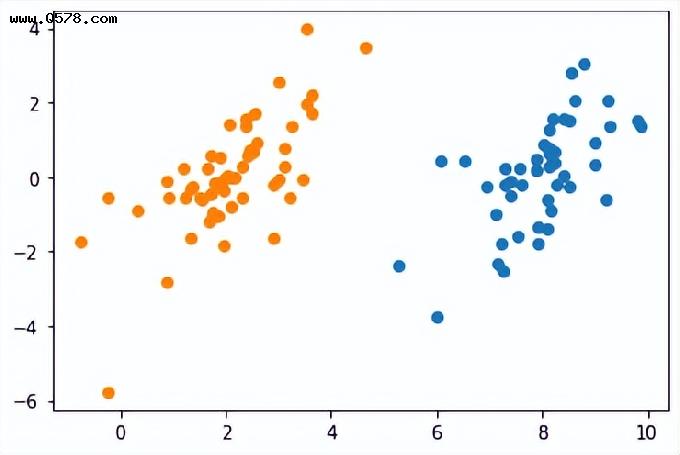
- 可视化数据集
import matplotlib.pyplot as pltimport numpy as np#读取数据def loadDataSet(fileName): dataMat = []; labelMat = [] fr = open(fileName) for line in fr.readlines(): #逐行读取,滤除空格等 lineArr = line.strip().split(”) dataMat.append([float(lineArr[0]),float(lineArr[1])]) #添加数据 labelMat.append(float(lineArr[2])) #添加标签 return dataMat,labelMat#数据可视化def showDataSet(dataMat,labelMat): data_plus = [] data_minus = [] for i in range(len(dataMat)): if labelMat[i] > 0: data_plus.append(dataMat[i]) else: data_minus.append(dataMat[i]) data_plus_np = np.array(data_plus) #转换为numpy矩阵 data_minus_np = np.array(data_minus)#转换为numpy矩阵 plt.scatter(np.transpose(data_plus_np)[0],np.transpose(data_plus_np)[1]) #正样本 plt.scatter(np.transpose(data_minus_np)[0],np.transpose(data_minus_np)[1]) #负样本 plt.show()dataMat,labelMat = loadDataSet(‘testSet.txt’)showDataSet(dataMat,labelMat)
这个数据集显然线性可分。
应用简化版SMO算法处理小规模数据集
import randomdef selectJrand(i,m): j=i while(j==i): #选择一个不等于i的j j = int(random.uniform(0,m)) return jdef clipAlpha(aj,H,L): if aj > H: aj = H if L > aj: aj = L return ajdataArr,labelArr =loadDataSet(‘testSet.txt’)labelArr
[-1.0, -1.0, 1.0, -1.0, 1.0, 1.0, 1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, 1.0, -1.0, 1.0, 1.0, -1.0, 1.0, -1.0, -1.0, -1.0, 1.0, -1.0, -1.0, 1.0, 1.0, -1.0, -1.0, -1.0, -1.0, 1.0, 1.0, 1.0, 1.0, -1.0, 1.0, -1.0, -1.0, 1.0, -1.0, -1.0, -1.0, -1.0, 1.0, 1.0, 1.0, 1.0, 1.0, -1.0, 1.0, 1.0, -1.0, -1.0, 1.0, 1.0, -1.0, 1.0, -1.0, -1.0, -1.0, -1.0, 1.0, -1.0, 1.0, -1.0, -1.0, 1.0, 1.0, 1.0, -1.0, 1.0, 1.0, -1.0, -1.0, 1.0, -1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, -1.0, -1.0, -1.0, -1.0, 1.0, -1.0, 1.0, 1.0, 1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0]
data = np.mat(dataArr)data[2,:]matrix([[ 7.55151, -1.58003]])
可以看出来,这里使用的类别标签是-1和1
SMO算法的伪代码:
创建一个alpha向量并将其初始化为 0 向量 当迭代次数小于最大迭代次数时 (外循环) 对数据集中的每个数据向量 (内循环): 如果该数据向量可以被优化: 随机选择另外一个数据向量 同时优化这两个向量 如果两个向量都不能被优化, 退出内循环如果所有向量都没被优化, 增加迭代数目, 继续下一次循环#简化版SMO算法def smoSimple(dataMatIn,classLabels,C,toler,maxIter): dataMatrix = np.mat(dataMatIn); labelMat = np.mat(classLabels).transpose() b = 0; m,n = np.shape(dataMatrix) alphas = np.mat(np.zeros((m,1)))#初始化alpha参数,设置为0 iterSmo = 0 #初始化迭代次数 while(iterSmo < maxIter): alphaPairsChanged = 0#用于记录alpha是否已经进行优化 #步骤1. 计算误差Ei for i in range(m): fXi = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b Ei = fXi – float(labelMat[i]) if ((labelMat[i]*Ei 0)): j = selectJrand(i,m) #步骤1. 计算误差Ej fXj = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b Ej = fXj – float(labelMat[j]) #保存更新前的alpha值,使用浅拷贝 alphaIold = alphas[i].copy() alphaJold = alphas[j].copy() #步骤2:计算上界H和下界L if (labelMat[i] != labelMat[j]): L = max(0,alphas[j] – alphas[i]) H = min(C,C + alphas[j] – alphas[i]) else: L = max(0,alphas[j] + alphas[i] – C) H = min(C,alphas[j] + alphas[i]) if L==H: print(“L==H”); continue #步骤3:计算eta eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T – dataMatrix[i,:]*dataMatrix[i,:].T – dataMatrix[j,:]*dataMatrix[j,:].T if eta >=0 : print(“eta>=0”);continue #步骤4:更新alpha_j alphas[j] -= labelMat[j]*(Ei-Ej)/eta #步骤5:修剪alpha_j alphas[j] = clipAlpha(alphas[j],H,L) if (abs(alphas[j] – alphaJold) < 0.00001) : print("j not moving enough") ; continue #步骤6:更新alpha_i alphas[i] += labelMat[j]*labelMat[i]*(alphaJold – alphas[j]) #步骤7:更新b_1和b_2 b1 = b – Ei – labelMat[i]*(alphas[i] – alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T – labelMat[j]*(alphas[j] – alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T b2 = b – Ej – labelMat[i]*(alphas[i] – alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T – labelMat[j]*(alphas[j] – alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T #步骤8:根据b_1和b_2更新b if (0 alphas[i]) : b = b1 elif (0 alphas[j]): b = b2 else: b = (b1 + b2)/2.0 #统计优化次数 #如果程序执行到for循环的最后一行都不执行continue语句,那么就已经成功地改变了一对alpha,同时可以增加alphaPairsChanged的值 alphaPairsChanged += 1 #打印统计信息 print("第%d次迭代 样本:%d, alpha优化次数:%d" % (iterSmo,i,alphaPairsChanged)) #更新迭代次数 #在for循环之外,需要检查alpha值是否做了更新,如果有更新则将iterSmo设为0后继续运行程序。只有在所有数据集上遍历maxIter次,且不再发生任何alpha修改之后,程序才会停止并退出while循环 if (alphaPairsChanged == 0): iterSmo += 1 else: iterSmo = 0 print("迭代次数:%d" % iterSmo) return b,alphasb,alphas = smoSimple(dataArr,labelArr,0.6,0.001,500)
L==H第0次迭代 样本:1, alpha优化次数:1第0次迭代 样本:3, alpha优化次数:2第0次迭代 样本:5, alpha优化次数:3L==H第0次迭代 样本:8, alpha优化次数:4L==Hj not moving enoughj not moving enoughL==HL==Hj not moving enoughL==H第0次迭代 样本:30, alpha优化次数:5第0次迭代 样本:31, alpha优化次数:6L==HL==H第0次迭代 样本:54, alpha优化次数:7L==HL==H第0次迭代 样本:71, alpha优化次数:8L==HL==HL==H第0次迭代 样本:79, alpha优化次数:9L==H第0次迭代 样本:92, alpha优化次数:10j not moving enoughL==H迭代次数:0第0次迭代 样本:1, alpha优化次数:1j not moving enoughj not moving enoughj not moving enoughj not moving enoughj not moving enoughL==HL==Hj not moving enoughj not moving enoughj not moving enoughj not moving enoughL==Hj not moving enoughL==HL==Hj not moving enoughj not moving enough第0次迭代 样本:37, alpha优化次数:2第0次迭代 样本:39, alpha优化次数:3第0次迭代 样本:52, alpha优化次数:4j not moving enoughj not moving enoughj not moving enoughj not moving enoughj not moving enough第0次迭代 样本:71, alpha优化次数:5j not moving enoughj not moving enoughj not moving enoughj not moving enoughj not moving enough迭代次数:0j not moving enoughj not moving enoughj not moving enough第0次迭代 样本:8, alpha优化次数:1L==Hj not moving enough第0次迭代 样本:23, alpha优化次数:2L==Hj not moving enoughj not moving enoughL==Hj not moving enoughj not moving enoughj not moving enough第0次迭代 样本:39, alpha优化次数:3L==Hj not moving enough第0次迭代 样本:52, alpha优化次数:4j not moving enough第0次迭代 样本:55, alpha优化次数:5L==HL==HL==HL==HL==Hj not moving enough第0次迭代 样本:79, alpha优化次数:6第0次迭代 样本:92, alpha优化次数:7迭代次数:0j not moving enoughL==Hj not moving enoughj not moving enoughL==Hj not moving enough第0次迭代 样本:23, alpha优化次数:1j not moving enoughj not moving enoughj not moving enoughj not moving enoughj not moving enoughj not moving enoughj not moving enoughL==HL==H第0次迭代 样本:51, alpha优化次数:2j not moving enoughj not moving enoughj not moving enoughj not moving enoughL==H第0次迭代 样本:69, alpha优化次数:3L==Hj not moving enough第0次迭代 样本:94, alpha优化次数:4j not moving enoughj not moving enough迭代次数:0j not moving enoughj not moving enoughj not moving enoughj not moving enoughj not moving enough
…
迭代次数:497j not moving enoughj not moving enoughj not moving enough迭代次数:498j not moving enoughj not moving enoughj not moving enough迭代次数:499j not moving enoughj not moving enoughj not moving enough迭代次数:500
bmatrix([[-3.83785102]])alphas[alphas>0]matrix([[0.1273855 , 0.24131542, 0.36872064]])np.shape(alphas[alphas>0])(1, 3)for i in range(100): if alphas[i] > 0.0: print(dataArr[i],labelArr[i])[4.658191, 3.507396] -1.0[3.457096, -0.082216] -1.0[6.080573, 0.418886] 1.0#分类结果可视化def showClassifer(dataMat, w, b): #绘制样本点 data_plus = [] #正样本 data_minus = [] #负样本 for i in range(len(dataMat)): if labelMat[i] > 0: data_plus.append(dataMat[i]) else: data_minus.append(dataMat[i]) data_plus_np = np.array(data_plus) #转换为numpy矩阵 data_minus_np = np.array(data_minus) #转换为numpy矩阵 plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1], s=30, alpha=0.7) #正样本散点图 plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1], s=30, alpha=0.7) #负样本散点图 #绘制直线 x1 = max(dataMat)[0] x2 = min(dataMat)[0] a1, a2 = w b = float(b) a1 = float(a1[0]) a2 = float(a2[0]) y1, y2 = (-b- a1*x1)/a2, (-b – a1*x2)/a2 plt.plot([x1, x2], [y1, y2]) #找出支持向量点 for i, alpha in enumerate(alphas): if abs(alpha) > 0: x, y = dataMat[i] plt.scatter([x], [y], s=150, c=’none’, alpha=0.7, linewidth=1.5, edgecolor=’red’) plt.show()#计算wdef get_w(dataMat, labelMat, alphas): alphas, dataMat, labelMat = np.array(alphas), np.array(dataMat), np.array(labelMat) w = np.dot((np.tile(labelMat.reshape(1, -1).T, (1, 2)) * dataMat).T, alphas) return w.tolist()w = get_w(dataMat,labelMat,alphas)showClassifer(dataMat,w,b)
